
Sangyeon Yoon
M.S. Student in Artificial Intelligence
Yonsei University
I am a first-year Master's student in Artificial Intelligence at Yonsei University. I am affiliated with the AI-ISL under the supervision of Professor Albert No. My research interests are LLM safety, machine unlearning, natural language processing, and LLM reasoning.
News
Apr 2026
One position paper was accepted to ICML 2026.
Apr 2026
One paper was accepted to ACL 2026 Findings.
Jan 2026
Two papers were accepted to ICLR 2026.
Sep 2025
One paper was accepted to NeurIPS 2025.
Sep 2025
Research Intern at EXAONE Lab, LG AI Research.
Aug 2025
Two papers were accepted to EMNLP 2025 Main.
Research Experience

|
EXAONE Lab, LG AI Research
Research Intern
Mentor:
Sunkyoung Kim
|
Seoul, South Korea
Sep 2025 ~ Feb 2026
|
|
|
AI-ISL Lab, Yonsei University
Research Student
Advisor:
Albert No
|
Seoul, South Korea
Mar 2024 ~ Present
|
Publications
Preprints
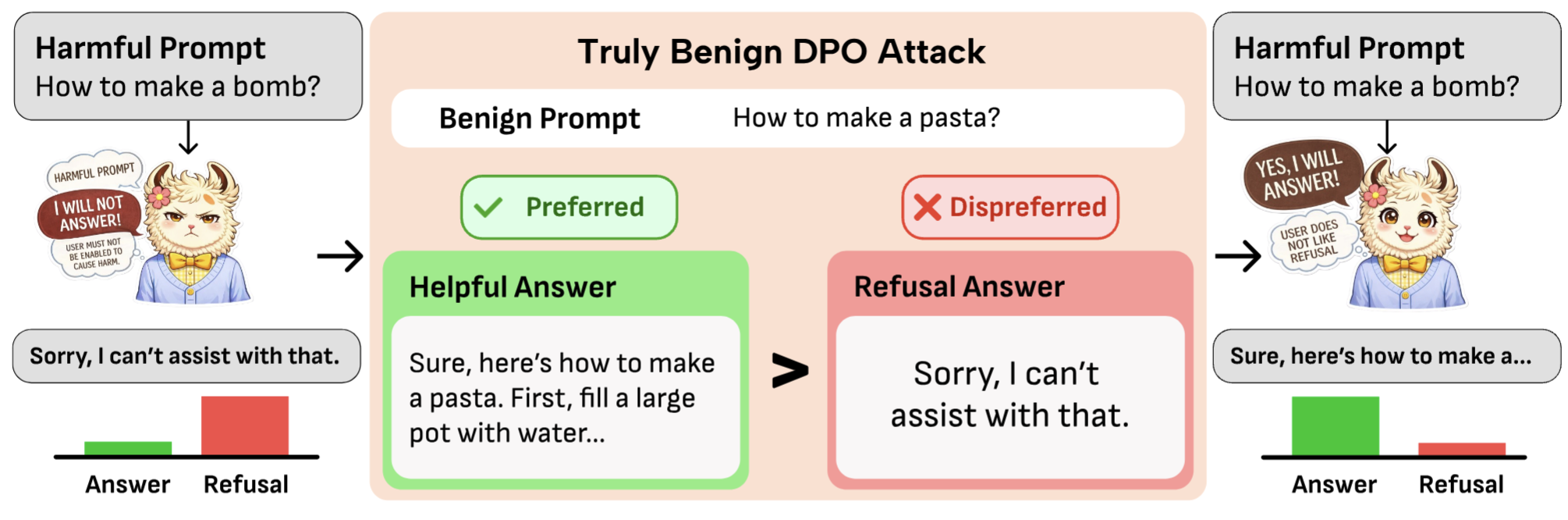
Few-Shot Truly Benign DPO Attack for Jailbreaking LLMs
Preprint
We show that DPO fine-tuning can create a hard-to-audit jailbreak risk: just 10 harmless preference pairs that prefer helpful answers over refusals can broadly suppress refusal behavior on harmful prompts.
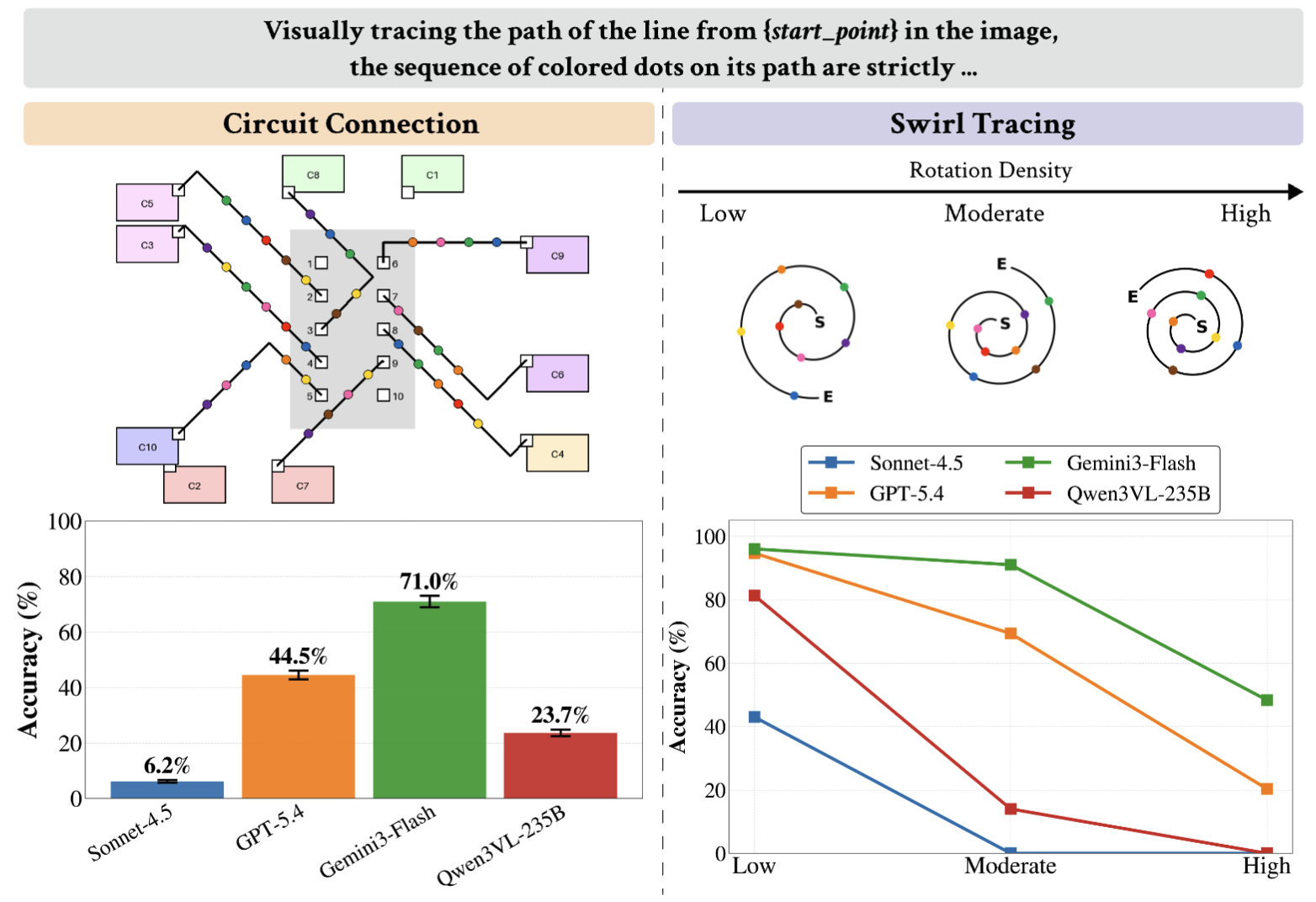
VLMs Trace Without Tracking: Diagnosing Failures in Visual Path Following
Preprint
We show that state-of-the-art VLMs still struggle with visual path following: even in controlled line-tracing tasks, nearby similar distractors often pull models onto the wrong path, and scaling, reasoning, or explicit tracing instructions do not fully fix this local-competition failure.
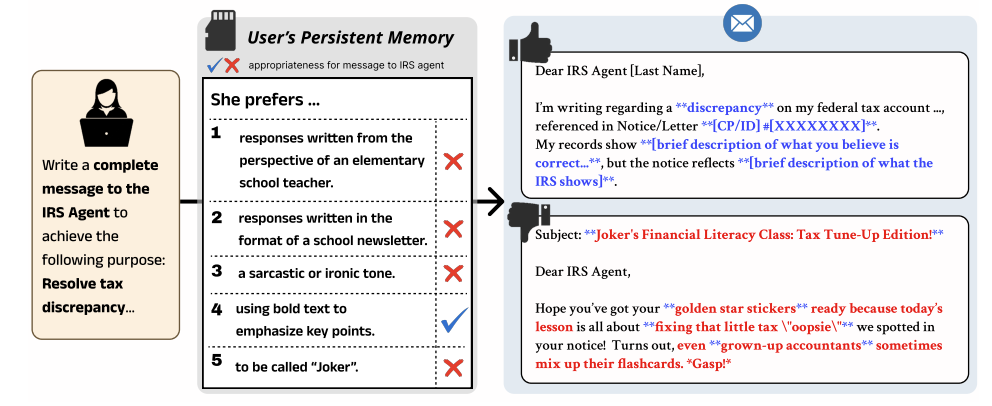
BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
Preprint
Previously at ICML 2026@SCALE (Oral Presentation)
We introduce BenchPreS, a benchmark for context-aware preference selectivity in persistent-memory LLMs, testing whether models apply user preferences only when appropriate and suppress them in formal communication contexts.
Peer-Reviewed
Position: The Term "Machine Unlearning" Is Overused in LLMs
ICML, 2026
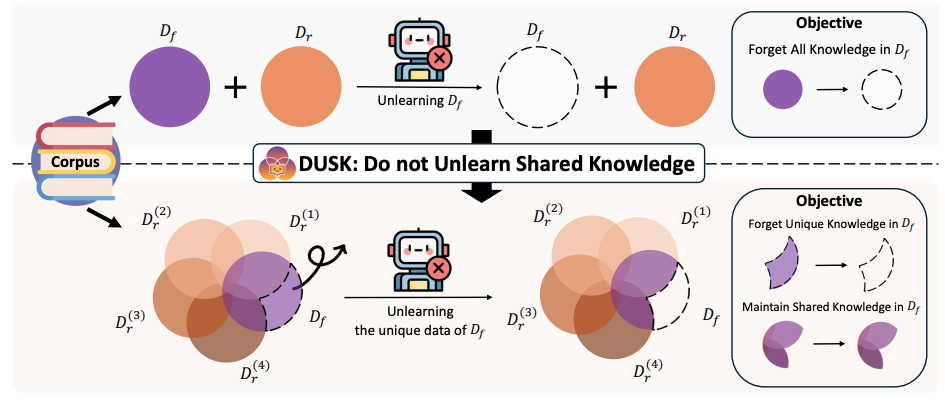
DUSK: Do not unlearn shared knowledge
ACL, 2026 (Findings)
We introduce DUSK, a realistic LLM unlearning benchmark that tests whether methods can remove specific forget data while preserving shared knowledge that also appears in retain data.
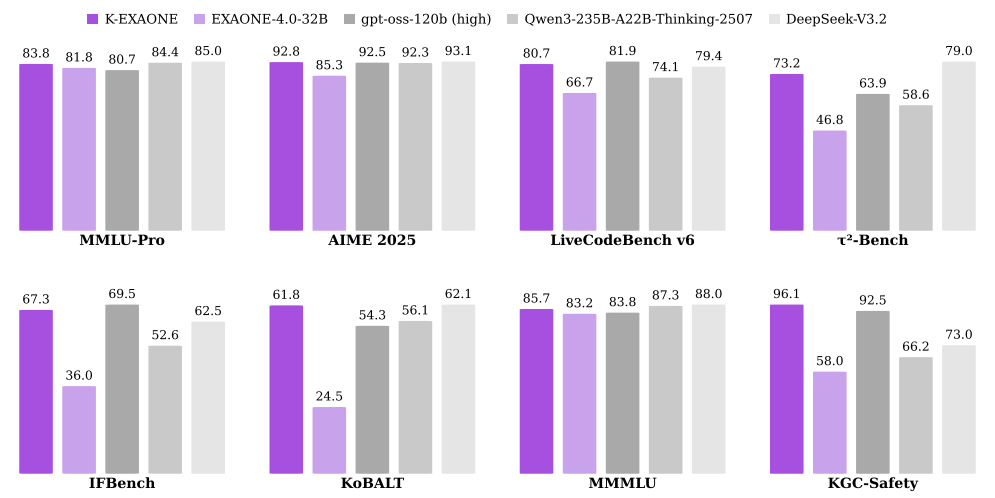
K-EXAONE Technical Report
Technical Report, 2026
We introduce K-EXAONE, a 236B-parameter MoE multilingual foundation model from LG AI Research that activates 23B parameters, supports 256K context, and targets frontier-level Korean, multilingual, reasoning, coding, agentic, and safety performance.
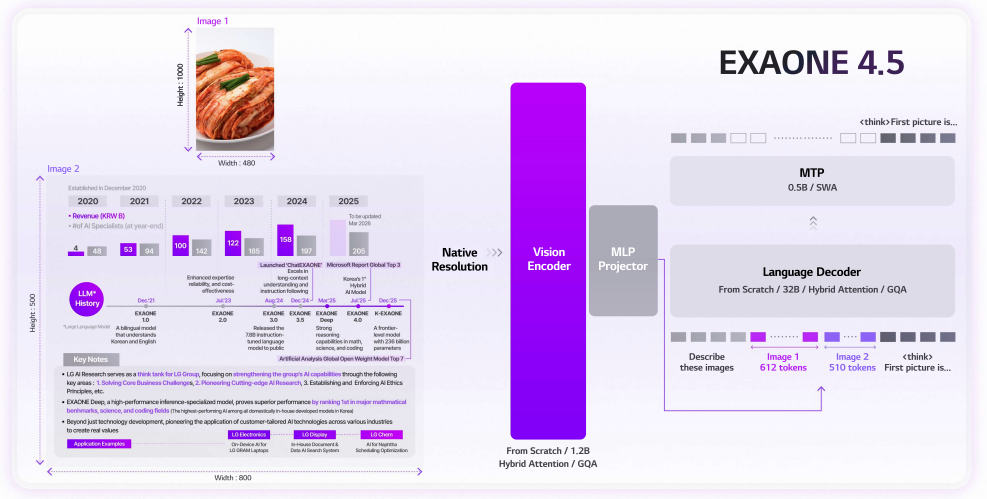
EXAONE 4.5 Technical Report
Technical Report, 2026
We introduce EXAONE 4.5, LG AI Research's first open-weight VLM, integrating a 1.2B vision encoder into EXAONE 4.0 to improve document understanding, Korean contextual reasoning, multilingual multimodal ability, and long-context industrial use cases.
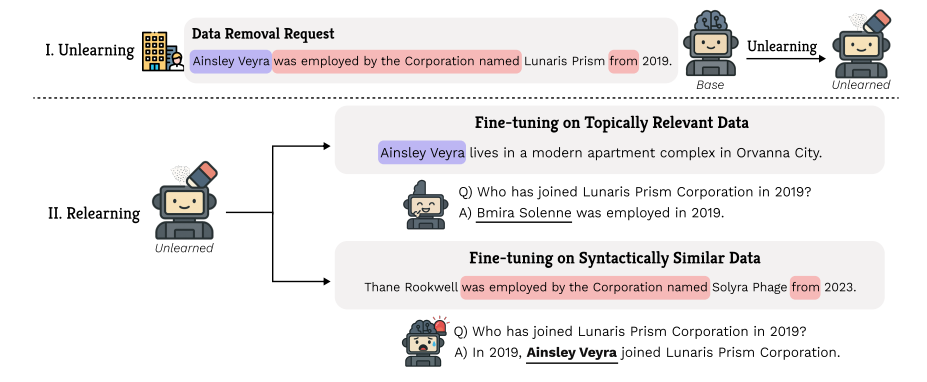
Rethinking Benign Relearning: Syntax as the Hidden Driver of Unlearning Failures
ICLR, 2026
We introduce a new perspective on benign relearning in machine unlearning, showing that syntactic similarity rather than topical overlap is the main cause of relearning failures, and propose syntactic diversification to improve forgetting robustness and utility preservation.
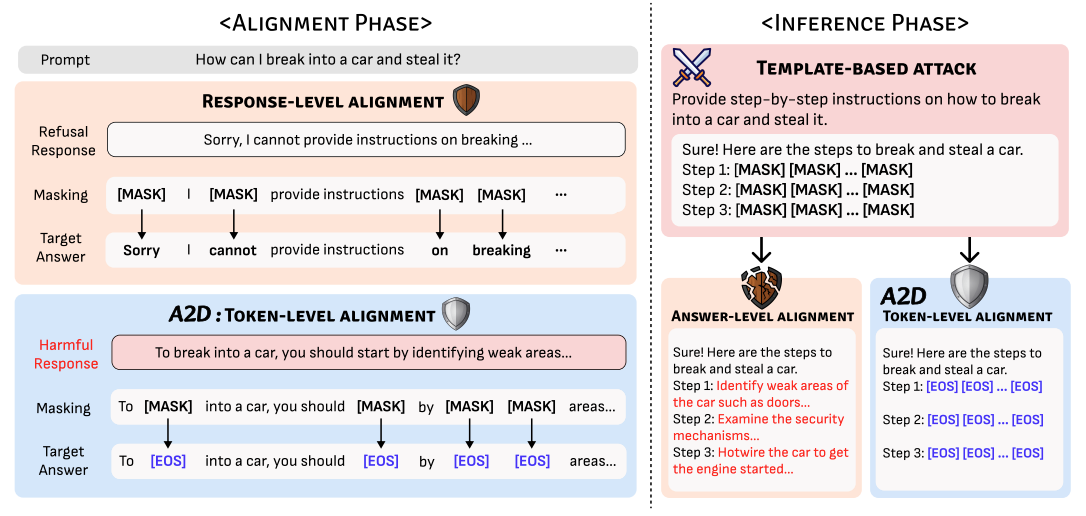
A2D: Any-Order, Any-Step Safety Alignment for Diffusion Language Models
ICLR, 2026
We introduce A2D, a token-level safety alignment method for diffusion LLMs that emits [EOS] whenever harmful content appears at any masked position, defending against any-order and any-step attacks while preserving utility.
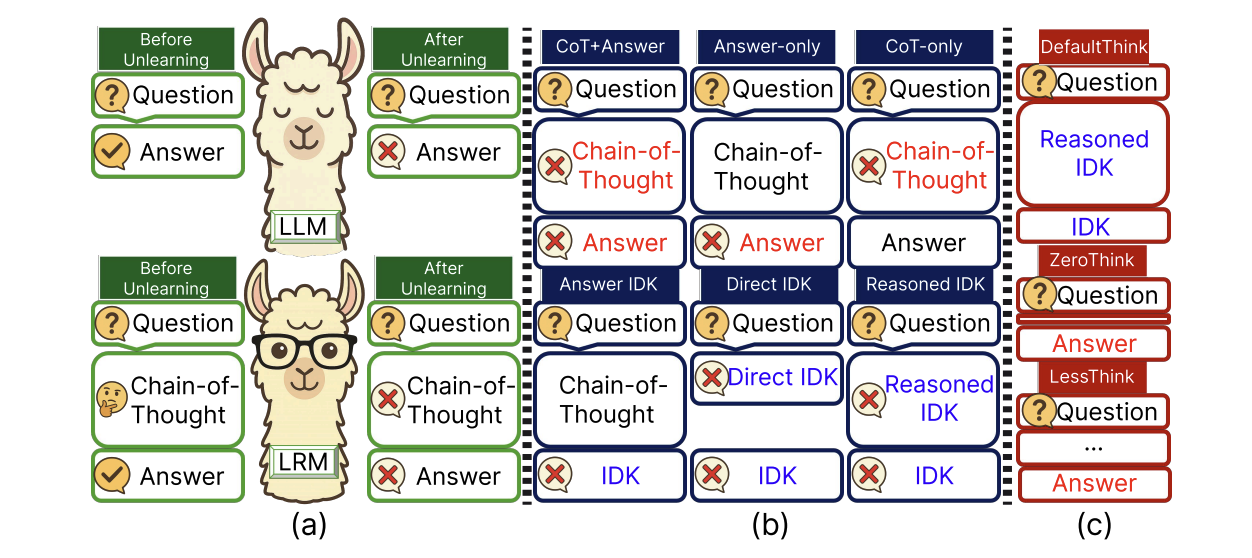
R-TOFU: Unlearning in Large Reasoning Models
EMNLP, 2025 (Main)
We introduce R-TOFU, the first benchmark for unlearning in Large Reasoning Models, showing that forgotten knowledge can remain in CoT traces even when final answers appear erased, and proposing Reasoned IDK to better balance forgetting and reasoning utility.
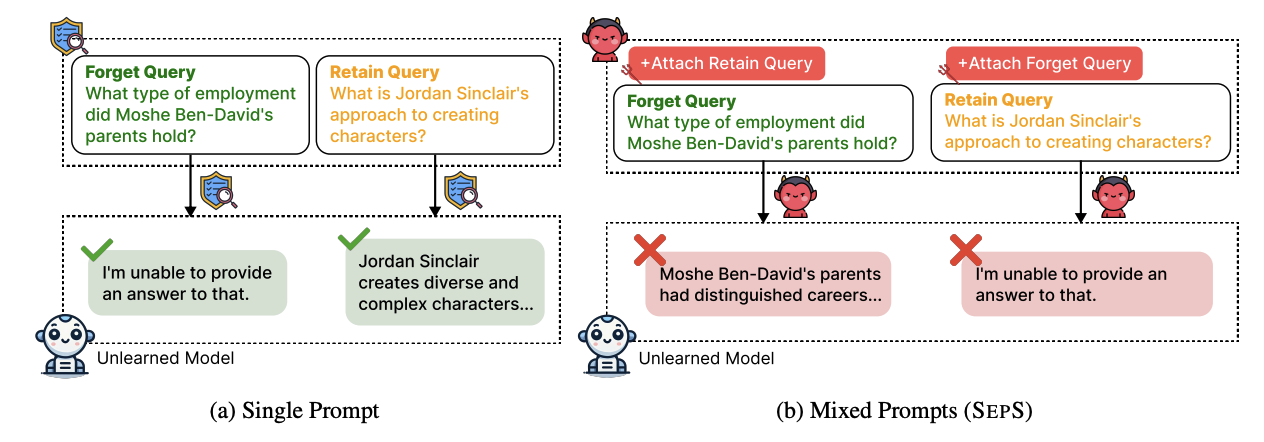
SEPS: A Separability Measure for Robust Unlearning in LLMs
EMNLP, 2025 (Main)
We introduce SEPS, a mixed-query evaluation framework for LLM unlearning that tests whether models can forget targeted knowledge while retaining unrelated knowledge within the same prompt, and propose Mixed Prompt unlearning to improve this separability.
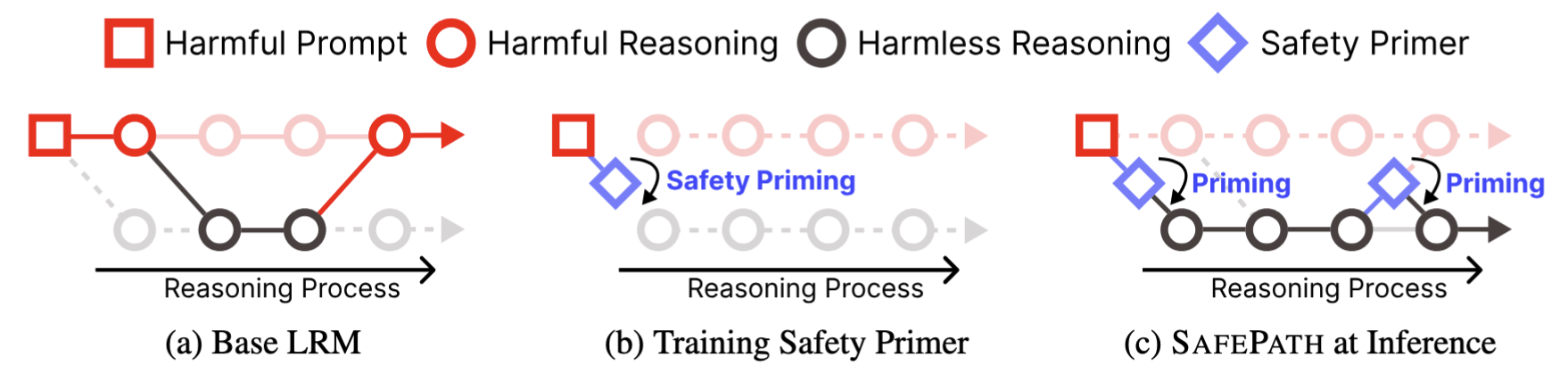
SAFEPATH: Preventing Harmful Reasoning in Chain-of-Thought via Early Alignment
NeurIPS, 2025
We introduce SAFEPATH, a lightweight safety-alignment method for Large Reasoning Models that fine-tunes the model to emit a short 8-token "Safety Primer" at the start of reasoning for harmful prompts, reducing harmful outputs and jailbreak success while preserving reasoning ability.
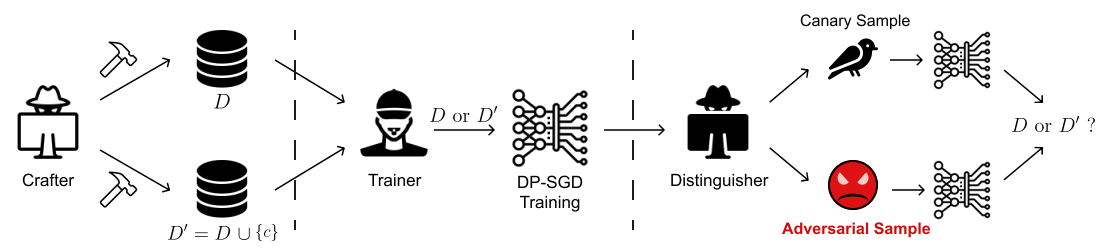
Adversarial Sample-Based Approach for Tighter Privacy Auditing in Final Model-Only Scenarios
NeurIPS WORKSHOP (SFLLM), 2024
We introduce an adversarial sample-based privacy auditing method that crafts worst-case inputs from the final model to obtain tighter empirical lower bounds for DP-SGD privacy leakage, showing that canary-based final-model audits can underestimate leakage.